
The Quake III Inverse Square Root Story
A small article on fast inverse square root, Newton refinement inspired by the magic trick in Quake III Arena.
Today, I would like to revisit the story behind one of the most famous low-level optimization tricks in video game history: the fast inverse square root implementation used in Quake III Arena.
As visible in the original source code from id Software’s Quake III fast inverse square root source code, a particularly unusual function named Q_rsqrt appears in the file q_math.c. This function takes a floating-point value as input and approximates its inverse square root:
At first glance, computing an inverse square root may seem oddly specific. However, this operation is fundamental in computer graphics and real-time physics simulation because it appears constantly during vector normalization. Given a vector , its normalized form with unitary length is defined as:
Computing the Euclidean norm requires a square root, and normalization additionally requires a division. In the context of real-time 3D rendering, especially during the late 1990s where floating-point hardware was significantly slower than today, these operations were computationally expensive.
Game engines such as those powering Quake III Arena relied heavily on geometric computations involving Euclidean spaces, rotations, lighting, collision detection, and camera transformations. As a consequence, inverse square root evaluations were performed extremely frequently, often millions of times per second.
The main story, however, lies in the remarkable trick used inside the Quake III implementation of this inverse square root function. As famously known, even the original source code itself seemed to express surprise at the method being used, with the legendary comment:
// what the fuck?written directly by one of the developers next to the infamous line involving the constant:
in integer representation.
At first sight, this hexadecimal value appears completely arbitrary and almost magical. Yet, behind this mysterious constant lies a clever mathematical approximation exploiting the structure of IEEE-754 floating-point representations.
In the following sections, we will progressively uncover how this constant was derived, why manipulating the bit representation of a floating-point number approximates a logarithmic transform, and how this seemingly obscure trick provides an efficient initial estimate for the inverse square root problem.
The IEEE-754 float representation
To firstly understand where this magical constant comes from, we must revisit the IEEE-754 floating-point representation used by modern computers to encode real numbers. This binary representation allows both integer and fractional values to be stored efficiently inside a fixed number of bits while preserving a very large dynamic range.
The IEEE-754 standard defines how floating-point numbers are represented, rounded, and manipulated at the hardware level. In the case of a 32-bit single-precision float, the number is decomposed into three distinct fields:
- 1 sign bit ,
- 8 exponent bits ,
- 23 mantissa (fraction) bits .
The encoded value is interpreted as:
The exponent is therefore stored using a biased representation with bias . The bits coming from , and are concatenated and stored to represent the real underlying value.
For example, the float is represented as:
Since the number is positive, the sign bit is: The biased exponent is: The significand is: therefore:
In IEEE-754 single precision, the leading is implicit, therefore only the fractional part is stored:
Hence, the 32-bit floating-point representation is obtained by concatenating the sign bit, exponent field, and mantissa field:
or equivalently in hexadecimal:
This is how a representable floating-point value is encoded on 32 bits. From this representation, one can derive the maximum finite value, the smallest positive normal value, spacing between adjacent representable values, and other information encoded by the format.
The Quake 3 Trick
The key idea behind the Quake 3 trick is that the integer representation of a floating-point number behaves approximately like an affine transform of its binary logarithm.
More generally, let be a normalized IEEE-754 float:
where:
- is the fractional mantissa,
- is the biased exponent field.
Taking the binary logarithm gives:
Now let denote the 23-bit mantissa field interpreted as an integer:
For positive normalized floats with sign bit zero, the 32-bit float bit pattern reinterpreted as an unsigned integer is therefore:
Substituting gives:
or equivalently:
At this point, one must be careful. The logarithmic term satisfies the local first-order approximation:
Therefore,
Using
we obtain:
Equivalently,
The correction term comes from the fact that the mantissa field stores , whereas the local linearization of has slope , not .
Since
This means the maximum gap between and is on the interval Test
Relation to inverse square root
We first examined the IEEE-754 floating-point standard, then showed that a floating-point bit pattern encodes one exact representable floating-point value and can also provide a rough approximation of the of that same value through direct manipulation of its bit representation.
Our main objective is to efficiently estimate:
where .
This problem can be reformulated as finding the root of the equation:
Defining:
the inverse square root problem becomes a root-finding problem:
This equation can be solved using the Newton-Raphson method.
The derivative of is:
Newton’s method iteratively refines an estimate using:
Substituting and gives:
which simplifies to:
and finally:
This is exactly the famous Newton refinement step used in the Quake 3 implementation q_math.c#L563
y = y * (1.5F - (x2 * y * y))In practice, the Newton refinement step can be iterated multiple times depending on the desired numerical precision of the estimation.
Such iterative methods require an initial estimate from which the successive refinements are computed in order to converge toward the solution of the Newton formulation.
The real ingenuity of the Quake 3 trick lies in the initialization of the Newton–Raphson iteration. A sufficiently accurate starting point drastically reduces the number of refinement steps required to approximate the inverse square root.
Starting from the refined affine approximation of the IEEE-754 bit representation,
where is the mantissa fraction of , we seek an approximation of
Using logarithmic identities,
Applying the same affine approximation to gives
with the mantissa fraction of .
Replacing using the approximation of yields
Hence the inverse square root initialization can be written as
where
Ignoring the mantissa correction gives the crude theoretical constant
The actual Quake 3 implementation instead uses
Thus,
This offset compensates for the mantissa-dependent term neglected in the simplified affine-logarithmic approximation. Since and vary with the input value, no single constant can exactly match every floating-point number. One possible approach is therefore to approximate the term with a fixed constant that minimizes the average error between the true correction and the quantity .
However, this is not the true objective of the Quake 3 method. In practice, the obtained approximation is only used as the initialization of a Newton–Raphson iteration, followed by a single refinement step. Consequently, the optimal constant is not the one minimizing the initial approximation error itself, but rather the one minimizing the final error after one Newton–Raphson iteration. This directly optimizes the actual target quantity: the inverse square root approximation.
The origin of the magic constant
To find the magical value, we will minimize the error using this Python code. The goal is to do an exhaustive search around the Quake magic value to evaluate the approximation error after one Newton iteration.
import numpy as np
import matplotlib.pyplot as plt
def qrsqrt(x, C):
x = x.astype(np.float32, copy=False)
y = (np.uint32(C) - (x.view(np.uint32) >> np.uint32(1))).view(np.float32)
return np.float32(y * (np.float32(1.5) - np.float32(0.5) * x * y * y))
def maxerr_lomont(C, a, b, bit_step=1, chunk=1_000_000):
max_err = 0.0
for s in range(a, b, chunk * bit_step):
bits = np.arange(s, min(s + chunk * bit_step, b), bit_step, dtype=np.uint32)
x = bits.view(np.float32)
err = np.abs(np.float32(1.0) - qrsqrt(x, C) * np.sqrt(x, dtype=np.float32))
max_err = max(max_err, float(err.max()))
return max_err
def ternary_int(lo, hi, f):
cache = {}
def F(c):
cache.setdefault(c, f(c))
return cache[c]
while hi - lo > 16:
m1, m2 = lo + (hi - lo) // 3, hi - (hi - lo) // 3
lo, hi = (lo, m2 - 1) if F(m1) < F(m2) else (m1 + 1, hi)
return min(((c, F(c)) for c in range(lo, hi + 1)), key=lambda t: t[1])
def group_by_error(constants, errors, decimals=18):
groups = {}
for C, E in zip(constants.astype(np.uint32), errors.astype(np.float64)):
groups.setdefault(round(float(E), decimals), []).append(int(C))
return groups
def hex_ticks(axis, values, n=8, rot=35):
ticks = np.linspace(values[0], values[-1], n, dtype=np.uint32)
axis.set_xticks(ticks.astype(np.int64))
axis.set_xticklabels([hex(int(t)) for t in ticks], rotation=rot, ha="right")
quake, lomont = 0x5F3759DF, 0x5F375A86
bit_start, bit_stop = 0x3F800000, 0x40800000
fast_C, fast_E = ternary_int(
quake - 50_000,
quake + 50_000,
lambda C: maxerr_lomont(C, bit_start, bit_stop, bit_step=4096),
)
print("fast:", hex(fast_C), fast_C, f"{fast_E:.18e}")
span = 256
Cs = np.arange(fast_C - span, fast_C + span + 1, dtype=np.uint32)
Es = np.array([maxerr_lomont(int(C), bit_start, bit_stop) for C in Cs])
best_i = int(np.argmin(Es))
best_C, best_E = int(Cs[best_i]), float(Es[best_i])
quake_E = maxerr_lomont(quake, bit_start, bit_stop)
lomont_E = maxerr_lomont(lomont, bit_start, bit_stop)
groups = group_by_error(Cs, Es)
print("\nGroups by error score, first 12 sorted:")
for E in sorted(groups)[:12]:
g = groups[E]
print(f"E={E:.18e} | n={len(g):3d} | from={hex(g[0])} to={hex(g[-1])}")
min_constants_exact = Cs[Es == best_E].astype(np.uint32)
tol = 1e-8
near_min = Cs[Es <= best_E + tol].astype(np.uint32)
print("\nMinimum error:")
print(f"E_min = {best_E:.18e}")
print("\nConstants reaching exact minimum:")
for C in min_constants_exact:
print(hex(int(C)), int(C))
print(f"\nConstants within {tol:.1e} of the minimum:")
print("count =", len(near_min))
print("from =", hex(int(near_min[0])), int(near_min[0]))
print("to =", hex(int(near_min[-1])), int(near_min[-1]))
for C in near_min:
i = int(np.where(Cs == C)[0][0])
print(hex(int(C)), int(C), f"{Es[i]:.18e}")
print("\n" + "=" * 70)
print("RESULTS")
print("=" * 70)
for name, C, E in (
("Quake", quake, quake_E),
("Lomont", lomont, lomont_E),
("Best", best_C, best_E),
):
print(f"\n{name}:")
print(hex(C), C, f"{E:.18e}")
print("\nDifferences:")
print("best_C - quake =", best_C - quake)
print("best_C - lomont =", best_C - lomont)
print("\nError improvements:")
print("quake_E - best_E =", quake_E - best_E)
print("lomont_E - best_E =", lomont_E - best_E)
zoom_pad = 24
z0, z1 = max(0, best_i - zoom_pad), min(len(Cs), best_i + zoom_pad + 1)
ZC, ZE = Cs[z0:z1], Es[z0:z1]
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
ax[0].plot(Cs.astype(np.int64), Es, color="black", lw=1.5)
for C, name, color in (
(quake, "Quake", "tab:blue"),
(lomont, "Lomont", "tab:orange"),
(best_C, "Best", "tab:red"),
):
ax[0].axvline(C, color=color, lw=2.5, label=f"{name} {hex(C)}")
ax[1].plot(ZC.astype(np.int64), ZE, color="black", lw=1.5)
for C, name, style in ((lomont, "Lomont", "--"), (best_C, "Best", ":")):
ax[1].axvline(C, color="black", ls=style, lw=2, label=f"{name} {hex(C)}")
for C in near_min:
if int(ZC[0]) <= int(C) <= int(ZC[-1]):
ax[1].axvline(int(C), color="black", ls="--", lw=1, alpha=0.45)
for axis, values, title, rot in (
(ax[0], Cs, "Local exhaustive validation", 35),
(ax[1], ZC, "Zoom around minimum", 45),
):
hex_ticks(axis, values, rot=rot)
axis.set(
xlabel="Magic constant",
ylabel=r"$\max_x |1 - \hat y\sqrt{x}|$",
title=title,
)
axis.grid(True)
axis.legend()
plt.tight_layout()
plt.show()fast: 0x5f375a5e 1597463134 1.750826835632324219e-03Groups by error score, first 12 sorted: E=1.751303672790526910e-03 | n= 6 | from=0x5f375a81 to=0x5f375a88 E=1.751363277435302951e-03 | n= 18 | from=0x5f375a77 to=0x5f375a8e E=1.751422882080077908e-03 | n= 16 | from=0x5f375a6c to=0x5f375a95 E=1.751482486724853949e-03 | n= 15 | from=0x5f375a63 to=0x5f375a9b E=1.751542091369628906e-03 | n= 15 | from=0x5f375a5b to=0x5f375aa0 E=1.751601696014404080e-03 | n= 16 | from=0x5f375a4e to=0x5f375aa7 E=1.751661300659179904e-03 | n= 15 | from=0x5f375a47 to=0x5f375aad E=1.751720905303955078e-03 | n= 17 | from=0x5f375a3e to=0x5f375ab3 E=1.751780509948730035e-03 | n= 14 | from=0x5f375a32 to=0x5f375ab8 E=1.751840114593506076e-03 | n= 16 | from=0x5f375a29 to=0x5f375abf E=1.751899719238281033e-03 | n= 18 | from=0x5f375a1f to=0x5f375ac5 E=1.751959323883057074e-03 | n= 13 | from=0x5f375a16 to=0x5f375aca
Minimum error: E_min = 1.751303672790527344e-03
Constants reaching exact minimum: 0x5f375a81 1597463169 0x5f375a83 1597463171 0x5f375a85 1597463173 0x5f375a86 1597463174 0x5f375a87 1597463175 0x5f375a88 1597463176
Constants within 1.0e-08 of the minimum: count = 6 from = 0x5f375a81 1597463169 to = 0x5f375a88 1597463176 0x5f375a81 1597463169 1.751303672790527344e-03 0x5f375a83 1597463171 1.751303672790527344e-03 0x5f375a85 1597463173 1.751303672790527344e-03 0x5f375a86 1597463174 1.751303672790527344e-03 0x5f375a87 1597463175 1.751303672790527344e-03 0x5f375a88 1597463176 1.751303672790527344e-03
====================================================================== RESULTS
Quake: 0x5f3759df 1597463007 1.752376556396484375e-03
Lomont: 0x5f375a86 1597463174 1.751303672790527344e-03
Best: 0x5f375a81 1597463169 1.751303672790527344e-03
Differences: best_C - quake = 162 best_C - lomont = -5
Error improvements: quake_E - best_E = 1.0728836059570312e-06 lomont_E - best_E = 0.0
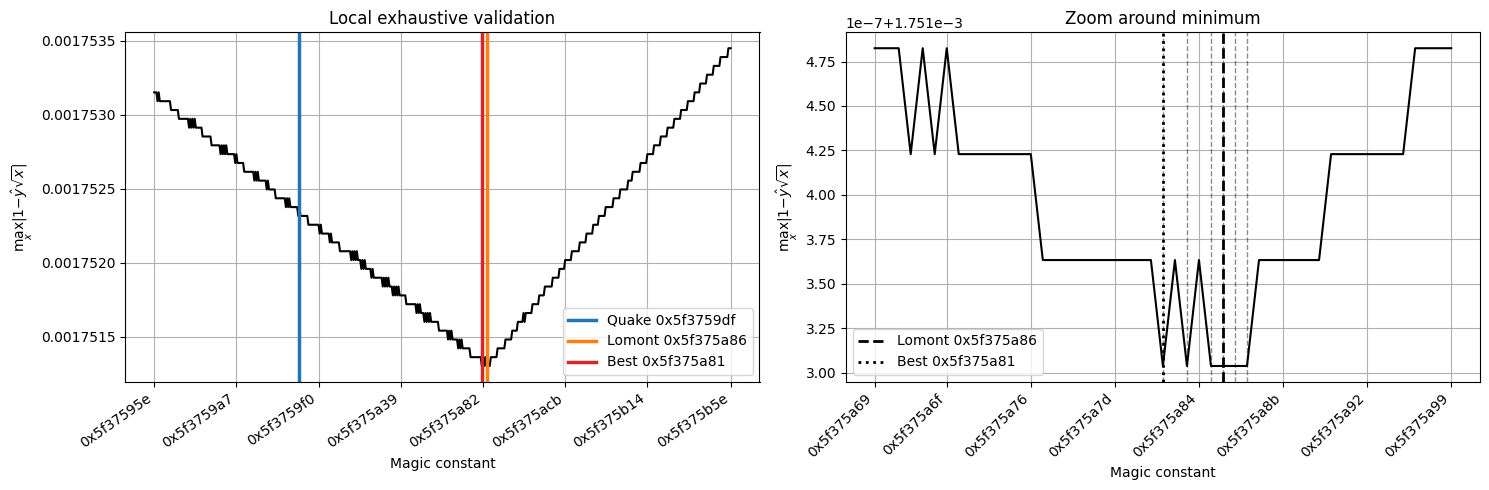
The error landscape around the Quake III magic constant reveals several important observations.
First, the error landscape exhibits a clear basin around the optimum. Since this is a discrete float32 experiment, the curve should not be interpreted as smooth or strongly convex in a rigorous mathematical sense. What matters is that the famous bit hack is not based on a completely arbitrary hexadecimal value, but rather on a carefully tuned numerical approximation.
Second, the original Quake constant:
is located quite close to the experimentally observed optimums in this sampled experiment and in the scanned interval, which is what Lomont found :
The difference between the two constants is only which represents a negligible perturbation compared to the magnitude of the constant itself. Most importantly, the corresponding approximation errors differ by less than:
after one Newton refinement step. In practice, such a difference is entirely insignificant for real-time 3D rendering applications.
This experiment is consistent with the idea that the Quake constant was obtained through empirical tuning near the theoretical logarithmic approximation:
followed by local numerical adjustments intended to minimize the inverse square root approximation error.
Finally, the graph highlights a remarkable property of the Quake III trick: despite relying on an apparently mysterious hexadecimal constant, the empirical value chosen for the initialization is extremely close to the best value found in this local scan, but it should not be presented as a proven global optimum over all positive float32 inputs.
References
- id Software.Quake III Arena source code, q_math.c. 1999. https://github.com/id-Software/Quake-III-Arena/blob/dbe4ddb10315479fc00086f08e25d968b4b43c49/code/game/q_math.c#L561